Resource | Link |
|---|---|
Weekly meetings (online) | Fridays 9-11AM Pacific |
Class website (public) | https://anyone-can-cook.github.io/rclass1/ |
Questions, discussion, announcements (private) | https://github.com/anyone-can-cook/rclass1_student_issues_f23 |
Class Zoom link | https://ucla.zoom.us/j/99687673673 |
EDUC 260A: Introduction to Programming and Data Management
Fall 2024
1 Course information
2 Course description
The primary goals of this course are (1) to teach fundamental skills of “data management,” which are important regardless of which programming language you use, and (2) to develop a strong foundation in the R programming language. The course is designed for students who never thought they would become programmers and no prior experience with R is required. For goal (1), most statistics courses teach you how to analyze data that are ready for analysis. In real research projects, data management – the process of cleaning, manipulating, and integrating datasets in order to create analysis datasets – is often more challenging than conducting analyses. For goal (2), R is a free, open-source, object-oriented programming language. R is the most popular language for statistical analysis and one of the most popular languages for “data science” applications (e.g., web-scraping, interactive maps, network analysis). Students will become proficient in data management and R programming through weekly problem sets, which will be completed in groups.
2.1 Extended description
Data management consists of acquiring, investigating, cleaning, combining, and manipulating data. Most statistics courses teach you how to analyze data that are ready for analysis. In real research projects, cleaning the data and creating analysis datasets is often more time consuming than conducting analyses. This course teaches the fundamental data management and data manipulation skills necessary for creating analysis datasets.
The course will be taught using R, a free, open-source programming language. R has become the most popular language for statistical analysis, surpassing SPSS, Stata, and SAS. What differentiates R from these other languages is the thousands of open-source “libraries” created by R users. R is one of the most popular languages for “data science” because R libraries have been created for web-scraping, mapping, network analysis, etc. By learning R you can be confident that you know a programming language that can run any modeling technique you might need and has amazing capabilities for data collection and data visualization. By learning fundamentals of R in this course, you will be “one step away” from web-scraping, network analysis, interactive maps, quantitative text analysis, or whatever other data science application you are interested in.
The data management and programming skills you learn in this course will transfer to other object-oriented programming languages (e.g., Python).
The course primarily use data and examples from education research. However, the course is designed to teach skills that are important for social science research more broadly and also for computational research within the humanities. We welcome students from across the university.
Recommended prerequisites (not absolutely required)
- One prior introductory statistics course (e.g., as an undergraduate)
- Proficiency in general computer skills is helpful, e.g., downloading files from internet, renaming files, saving them to a folder of your choosing, finding this folder on your computer, etc.
3 Instructor and teaching assistants
3.1 Instructor
Ozan Jaquette
- Pronouns: he/him/his
- Office: Moore Hall, Room 3038
- Email: ozanj@ucla.edu
- Office hours:
- Zoom office hours:
- And by appointment (afternoons)
3.2 Teaching assistants
NAME
- Pronouns:
- Email:
- Office hours:
- Zoom office hours:
- And by appointment
NAME
- Pronouns:
- Email:
- Office hours:
- Zoom office hours:
- And by appointment
4 Course learning goals
- Understand fundamental concepts of object-oriented programming
- What are the basic object types and how do they apply to statistical analysis?
- What are object attributes and how do they apply to statistical analysis?
- Become familiar with Base R approach to data manipulation and Tidyverse approach to data manipulation
- Investigate data patterns
- Sort datasets in ways that generate insights about data structure
- Select specific observations and specific variables in order to identify data structure and to examine whether variables are created correctly
- Create summary statistics of particular variables to diagnose errors in data
- Create variables
- Create variables that require calculations across columns
- Create variables that require processing across rows
- Visualize data
- Create plots using the ggplot2 library
- Customize plots through color palettes, labels, line shapes, etc.
- Combine multiple datasets
- Join (merge) datasets
- Append (stack) datasets
- Manipulate the organizational structure of datasets
- Summarize and collapse observations by group
- Reshape and “tidy” untidy data
- Learn guidelines and practical strategies for ensuring data quality when cleaning data and creating analysis variables
- Become proficient at using GitHub issues– the industry standard platform used by programmers to collaborate on projects– to ask questions about course material and to collaborate with your classmates
Another broad goal of the course is for students to begin developing practical proficiency in “computational thinking.” The California Computer Science Standards define computational thinking as “the human ability to formulate problems so that their solutions can be represented as computational steps or algorithms to be executed by a computer.” This course will encourage students to work on the following elements of computational thinking:
- Before you start writing code to accomplish some task, write out the individual steps that must be completed to accomplish the task
- When a particular piece of code is not working, develop a problem-solving approach where you change one element of the code at a time in order to systematically isolate and fix the problem
- For when you conceptually understand what you need to do but you don’t know the code to accomplish the task, develop a set of “go to” practices to help you figure it out, for example:
- Ask Google
- Post a question on the course GitHub “issues” page
- Become proficient at searching the course lecture slides and course textbook for answers
- When you know the right function, but not how to use it, become proficient at reading function documentation
4.1 Course structure
Overview. Course structure consists of weekly asynchronous course materials and weekly synchronous meetings. Each week we will focus on a particular topic (e.g., creating variables; writing functions). For each weekly topic, students will complete a problem set. Problem sets will be completed in groups and focus on practical application of concepts/skills from the topic of the week.
Asynchronous course materials. Asynchronous course materials will focus on the topic for that week (e.g., processing across rows). Course materials will consist of three types of resources:
- Detailed lecture slides (PDF or HTML) with sample code
- Pre-recorded video lecture of the instructor working through these slides
- The “.Rmd” file that created the PDF/HTML lecture slides.
- The .Rmd file will contain all “code chunks” and links to all data utilized in the lecture. Thus, students will “learn by doing” in that they will run R code on their own computer while they work through lecture materials on their own.
Synchronous meetings. Synchronous class meetings will be on Zoom. Attendance during the entire period is required, but students may ask instructor/TAs for exceptions due to scheduling conflicts.
During synchronous class time, students will have the option of (A) attending live lecture from the instructor or (B) working through lecture materials/problem sets in Zoom breakout rooms in small groups (e.g., problem set groups) or on their own. For the first three weeks of class, students will not have the option of working in Zoom breakout rooms.
For students who decide to work in Zoom breakout rooms, you will use this time to work through course materials (e.g., lecture slides, video lectures) and/or the associated problem set as you see fit. The synchronous workshops are also a great time to ask questions about course material or practical applications. TAs will be moving from one breakout room to the next, providing help. Each group can develop their own approach to how they want to use the synchronous workshop time. Some groups may work relatively independently, while others may work collaboratively. Some groups may agree to work through all asynchronous lecture materials beforehand so they can devote all workshop time to making progress on the problem set. The one requirement I make: do not do the problem set before working through the associated lecture material.
4.2 How to succeed in this class
In just a few words, the keys to success in this class are: start early, ask for help, help others
Here are some substantive tips to help you succeed:
- Work through weekly asynchronous lecture materials as soon as you can
- The weekly asynchronous lecture materials (lecture PDF/HTML, lecture .Rmd file with code, video lecture) are the core of this course. Lecture materials are designed for you to run the code on your computer as you work through the lecture. Therefore, treat each lecture as an active learning experience rather than passively reading slides.
- Start the weekly problem set early so that have time to seek help on questions you are struggling with
- If you can’t figure something out, ask for help!
- Discuss with your problem set group
- Ask a question on GitHub
- Come to office hours
- Be supportive of your classmates; let’s create a classroom environment where we all help each other succeed!
5 Classroom environment
We all have a responsibility to ensure that every member of the class feels valued, respected, and comfortable feeling uncomfortable. Be mindful that our words affects others in ways we might not fully understand. We have a responsibility to express our ideas in a way that doesn’t make disparaging generalizations and doesn’t make people feel excluded. As an instructor, I am responsible for setting an example through my own conduct.
Learning data management, while trying to get a handle on R and unfamiliar data, can feel overwhelming! We must create an environment where students feel comfortable asking questions and talking about what they did not understand. Discomfort is part of the learning process. Unburden yourself from the weight of being an “expert.” Focus your energy on improving and helping your classmates improve.
5.1 Towards an anti-racist, anti-heteronormative learning experience
This course teaches data management and R programming, tools that are often perceived as objective, independent of context and content. This is not true. Structural racism, white supremacy, and heteronormative ideas of gender identity and sexual orientation are rooted in every aspect of data. Seemingly objective rules (e.g., “the right way to handle data”) affect the way data are gathered, how variables are created, the questions asked (or not asked), etc.
At times, this course will utilize data that reflect systemic gaps based on race, ethnicity, immigration status, and gender identity, among other aspects of identity. It is critical that we acknowledge that: the social and economic marginalization reflected in data is rooted in systemic oppression that upholds white supremacy and heteronormativity; and that the processes used to create these data (e.g., how data collected, the categories chosen to represent identity) are often based on notions of white supremacy and heteronormativity. We should all be reflecting about our own role in upholding these systems. When you encounter a data management strategy that may cause harm, we encourage you to raise concerns. It may be that your instructor/TAs may need to think more critically about strategies they have been using for a long time!
6 Course website and communication
6.1 Course website
All course related material can be found on the course website. Pre-recorded lecture videos, lecture slides (PDF/HTML), and .Rmd files will be posted on the class website under the associated sections. Additional resources (e.g., syllabus) may also be posted on the class website.
6.2 Course discussion
We will be using GitHub issues for questions, class discussion, and class announcements HERE.
GitHub issues: GitHub issues are traditionally used by collaborators of a repository for managing tasks for a project. Our rational for using issues is twofold: 1) help track and organize questions related to course material and problem sets and 2) promote classroom participation. Students are encouraged to contribute to issues by posting questions, sharing helpful resources, and/or taking a stab at answering questions posted on issues. Some features include:
- Adding labels
- Assigning or mentioning users to an issue
- Referencing other issues
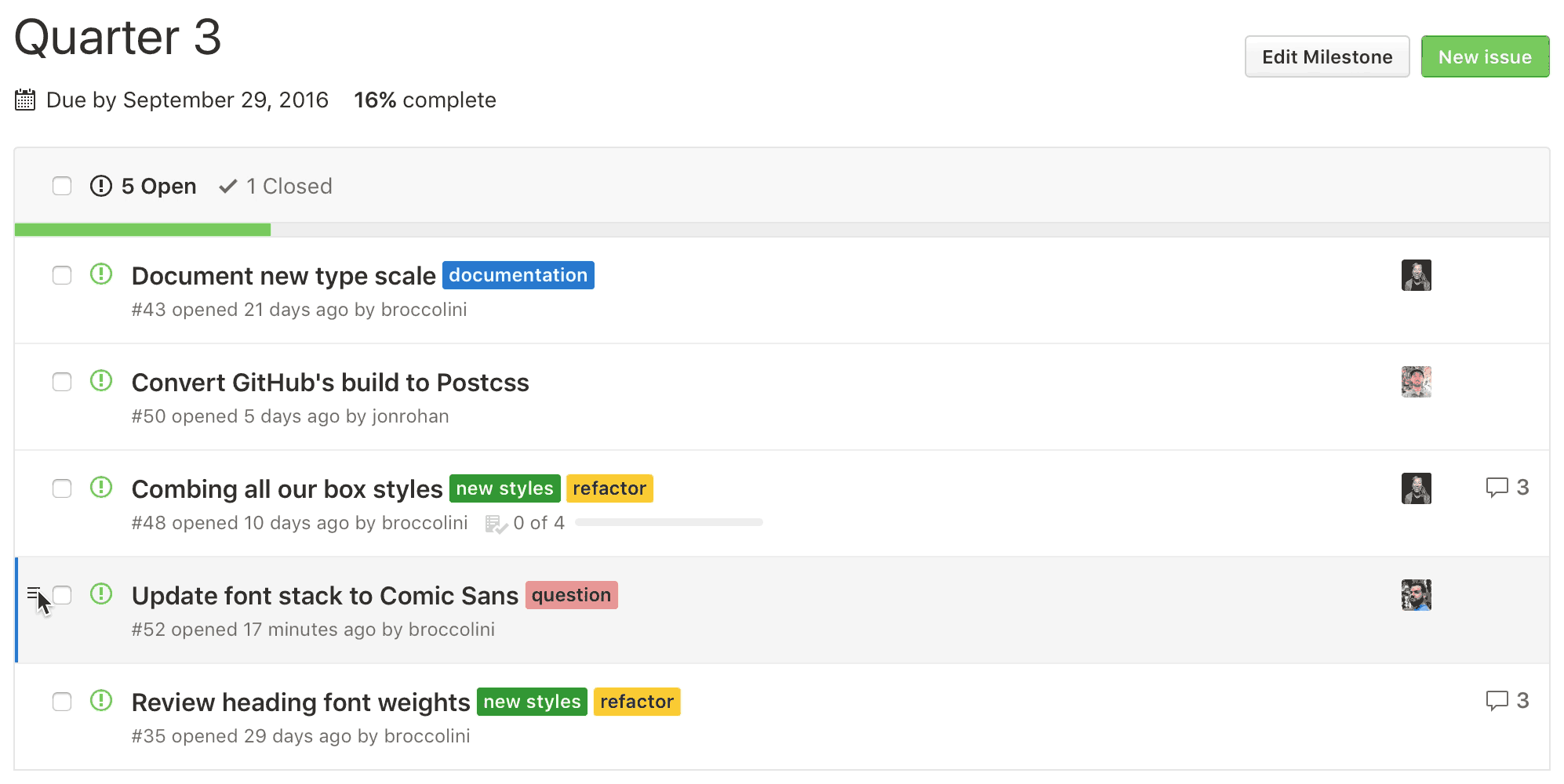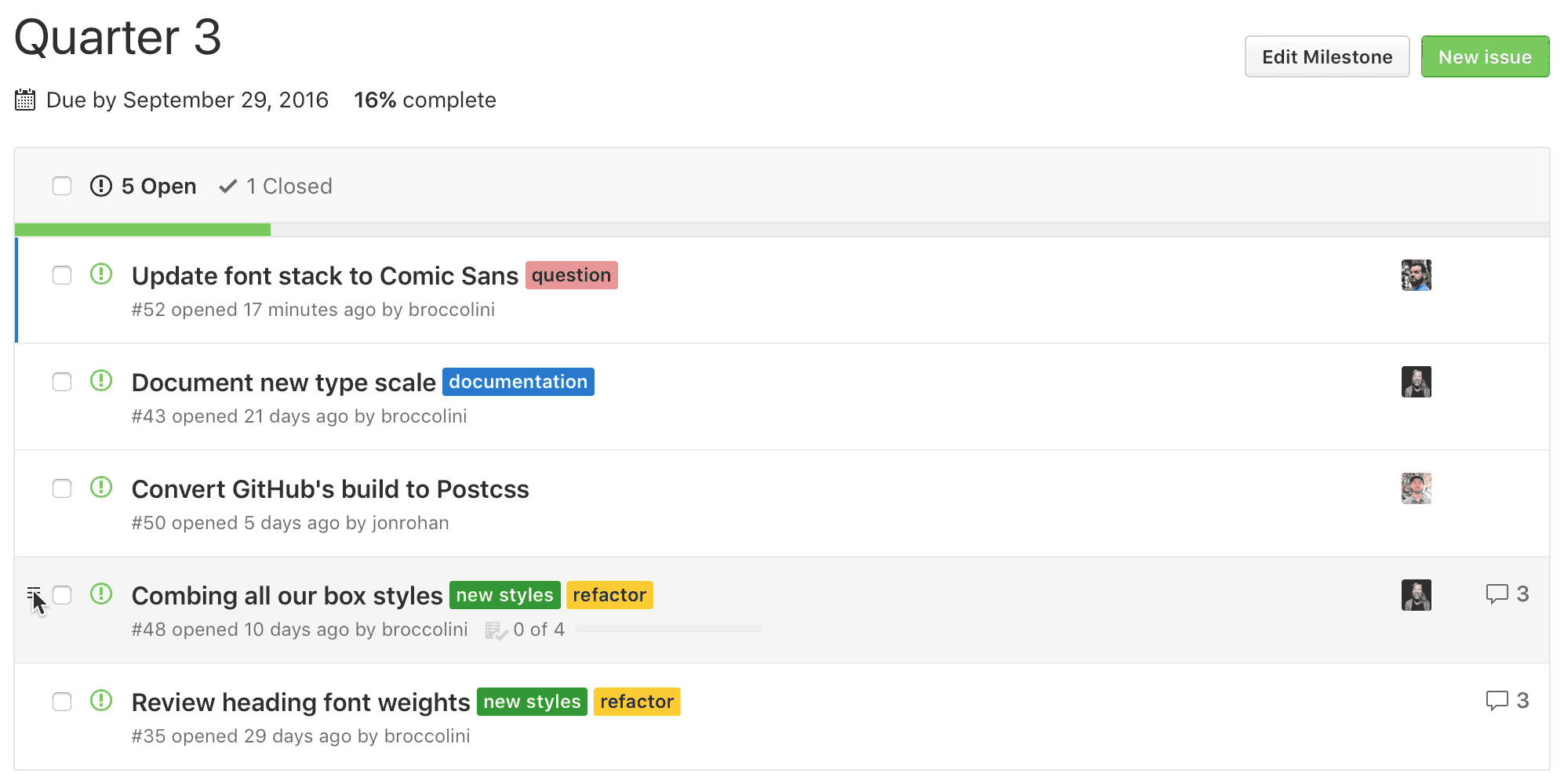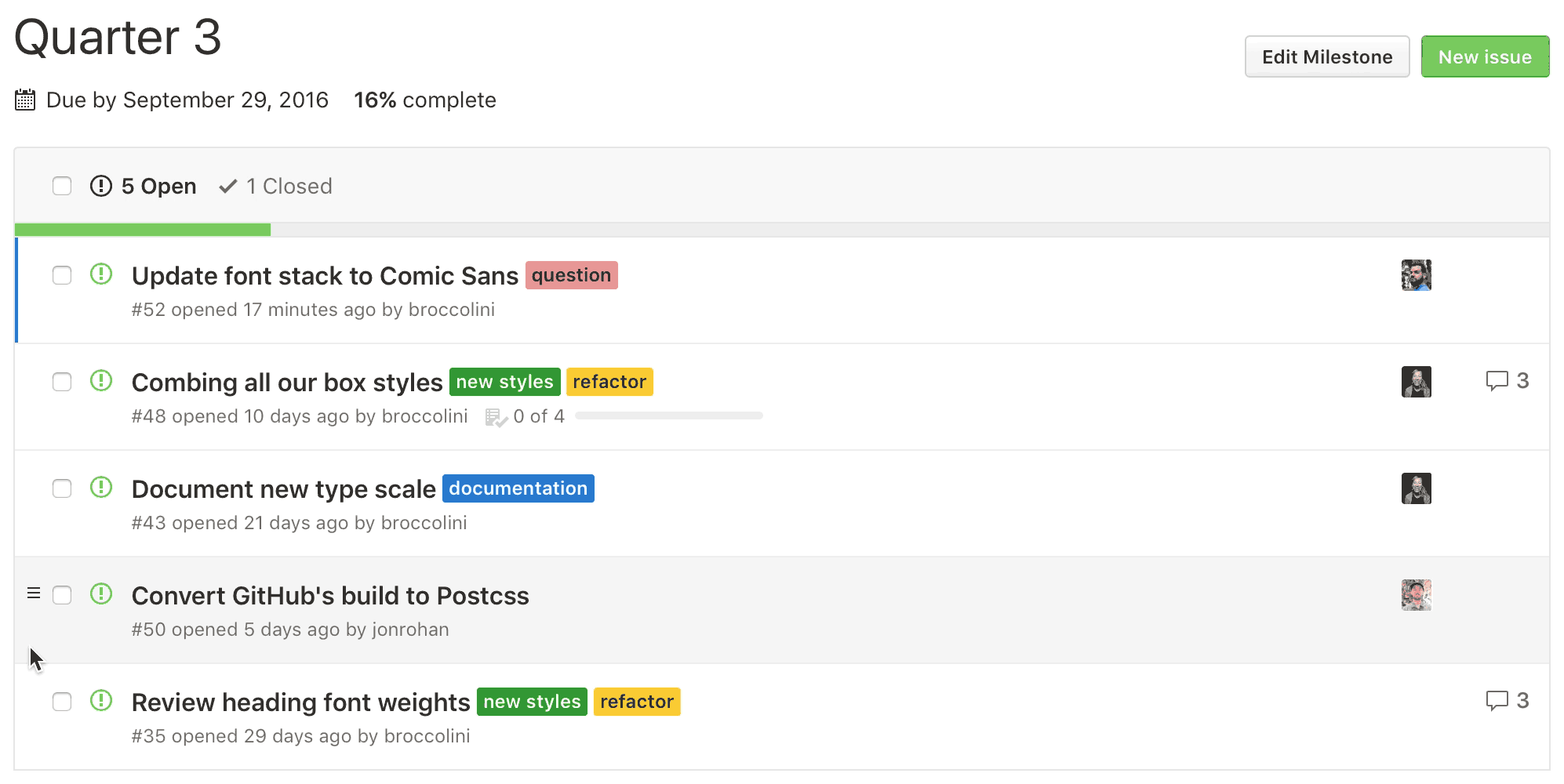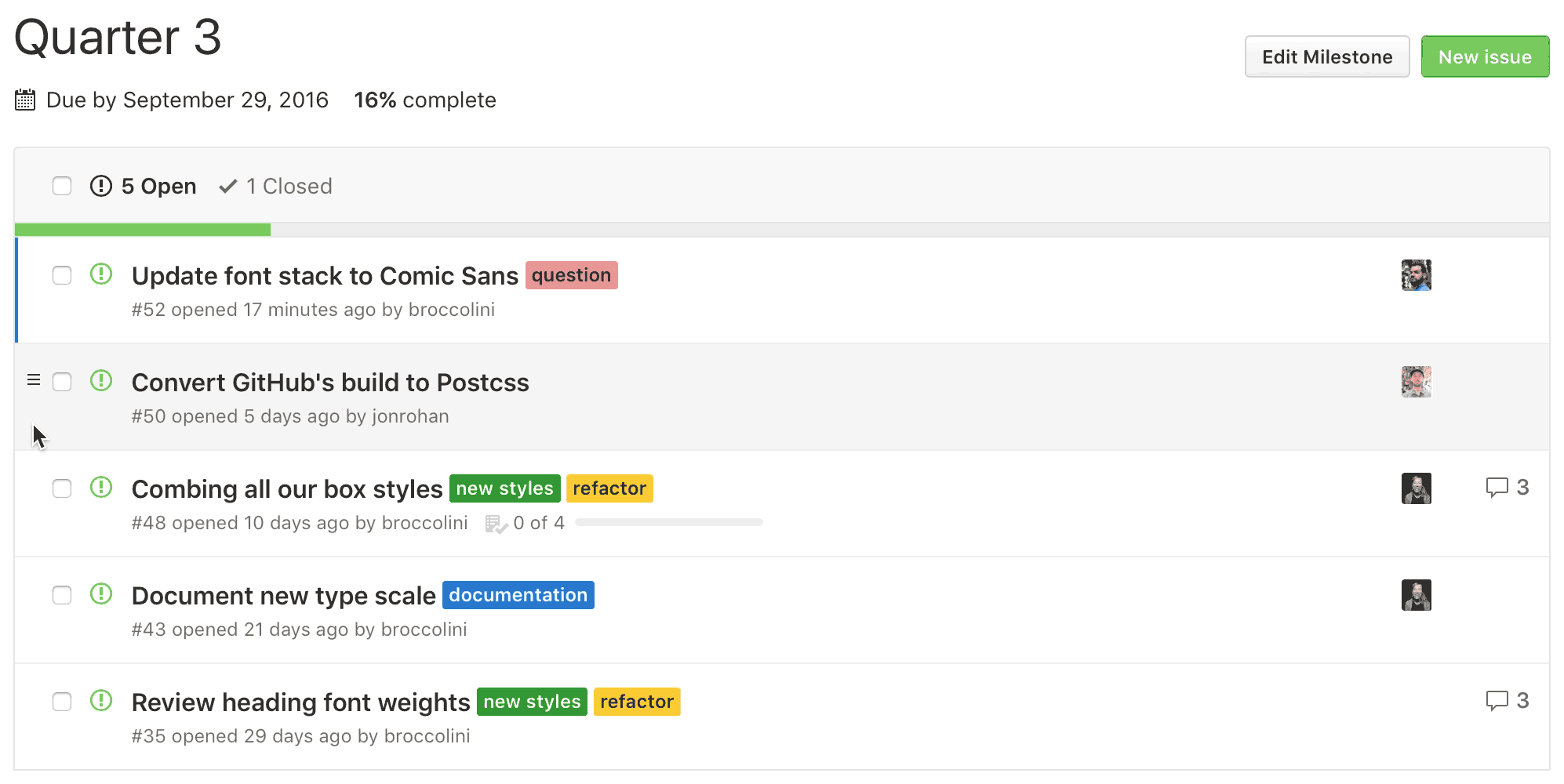
- Adding labels
6.3 Communication with instructor and TA
For questions about course content, please post question on Github issues (we will provide guidance about how to do this). If you have a personal question or issue, you can email the instructor or TA directly. Additionally, we are available for office hours or by appointment if there is anything you would like to discuss with us in private.
Limits to answering questions on github
- Instructor/TAs may not answer questions about the problem set that are posted Thursday afternoon or later.
- But do post the question, because one of your classmates will likely answer it!
- Some problem sets may have bonus/extra credit questions. Instructor/TAs will not answer questions about bonus questions.
- Instructor/TAs may not answer questions about research/analysis you are conducting outside of class
- But no harm in asking! We may have time to answer or one of your classmates might help.
7 Course materials
Course readings will be assigned from:
- R for Data Science by Garrett Grolemund and Hadley Wickham [FREE!]
- R Markdown: The Definative Guide by Yihui Xie, J. J. Allaire, and Garrett Grolemund [FREE!]
- Other articles/resources we post
Required software we will be using:
8 Assignments and grading
Course grade will be based on the following components:
- Weekly problem sets (90 percent of total grade)
- Participation (10 percent of total grade)
8.1 Problem sets (90 percent of total grade)
Students will complete 10 problem sets (the last one due during finals week). Problem sets are due by 9am each Friday, right before we start class. In general, each problem set will give you practice using the skills and concepts introduced in course materials for thate week. For example, after the lecture on joining (merging) datasets, the problem set for that week will require that students complete several different tasks involving merging data. Additionally, the weekly problem sets will require you to use data manipulation skills you learned in previous weeks. Link to problem set expectations and helpful resources HERE.
Problem set groups
- With the exception of the first problem set, students will complete problem sets in groups of 3. We highly encourage students who are abroad to form their own group to set a time to work on the problem sets together.
- Students have the option of not being part of a problem set group.
- We will form groups during the second synchronous class and you will keep the same group throughout the quarter. However, each student will submit their own assignment. You are encouraged to work together and get help from your group. However, it is important that you understand how to do the problem set on your own, rather than copying the solution developed by group members.
- Since you will be working together, it is understandable that answers for many questions will be the same as your group members. However, if I find compelling evidence that a student merely copied solutions from a classmate, I will consider this a violation of academic integrity and that student will receive a zero for the homework assignment.
A general strategy I recommend for completing the problem sets is as follows: (1) after lecture, do the reading associated with that lecture; (2) try doing the problem set on your own; (3) communicate with your group to work through the problem set, with a particular focus on areas group members find challenging.
Grading policies
- For students working in a problem set group, one submission from each problem set group will be chosen at random. The grade on that problem set submission will be the grade for all members of the group.
- If a member of a problem set group has not submitted the problem set by the time the TAs conduct grading, that submission will be grades separately once it is submitted
- The lowest problem-set grade will be dropped from the calculation of your final grade.
- Students who are not part of a problem set group will have their problem sets graded individually. A random subset of 4 or 5 problem sets will be graded. For students who work individually, the lowest problem set grade will not be dropped from calculation of final grade.
- Weekly required participation on github will be part of your problem set grade
- Policy on late assignments
- Problem sets submitted after 11:59PM on Friday will lose one percentage point (e.g., max grade becomes 99% instead of 100%)
- Starting at 12AM Monday morning, problem sets will lose an additional percentage point for each week-day it is not submitted
- e.g., for a problem set submitted at 10AM on Monday, the max grade becomes 98%
- e.g., for a problem set submitted at 10AM on Tuesday, the max grade becomes 97%
- For late submissions due to an unexpected emergency, you will not lose points. Please contact the instructor and/or TAs and we will work it out together.
8.2 Participation (10 percent of total grade)
Broadly, we expect students to participate by being attentive, supportive of classmates, by asking questions, and by answering questions posed by classmates.
Practically speaking, the vast majority of your participation grade will depend on weekly participation on Github. Each week, students are required to post one communication on Github. This could be asking a question about the problem set, answering a question posed by a classmate, or a post describing something you learned while working through the week’s material/problem set. If you post at least one communication on Github each week, you will earn an “A” for participation for the quarter.
In addition, students can work towards an 100% participation grade for the quarter by asking/answering questions during synchronous lecture (e.g., zoom chat) or by consistently being helpful/supportive to your classmates on Github.
8.3 Grading scale
Letter Grade | Percentage |
|---|---|
A | 93<=100% |
A- | 90<93% |
B+ | 87<90% |
B | 83<87% |
B- | 80<83% |
C+ | 77<80% |
C | 73<77% |
C- | 70<73% |
D | 60<70% |
F | 0<60% |
9 Course topics
Below is an overview of course topics. Topics and schedule are subject to change at the discretion of the instructor. Topics may be cut if we need to devote more time to learning the most central topics. It is unlikely that additional topics will be added. The official course schedule, including weekly required reading and optional reading, will be posted on the course website.
Week 1: Introduction to R
- Introduction to R and R data structures
- Execute R commands, understand R objects and data structures, use R functions
- Introduce atomic vectors, lists, and functions for investigating objects (e.g., length, type, str)
Week 2: Investigating objects using Base R & Subsetting with subset operators
- Data investigation and manipulation using Base R
- Investigate R object type and structure, isolate elements using Base R subset operators, and create new variables in Base R
Week 3: Enter the Tidyverse Part I: Pipes & Dplyr
- Data investigation and manipulation using tidyverse
- Select, filter, and sort data using
tidyversefunctions, chain functions together using pipes (%>%)
Week 4: Enter the Tidyverse Part II: variable creation
- Create new variables using
mutate() - Create new variables conditionally using
if_else(),recode(), andcase_when()
Week 5: Processing across rows
- Calculate aggregate statistics from multiple rows of data
- Group rows of data using
group_by(), create aggregate statistics usingsummarize()
Week 6: Attributes and class
- Understand the class and attributes of R objects
- Investigate R object class and attributes, work with factor variables, label variables and values of a dataframe using the
labelledpackage
Week 7: Create plots w/ ggplot
- Understand the layered grammar of graphics for visualizing data with ggplot2
- Make plots with the
ggplotfunction (e.g., bar plots, scatter plots) - Customize plots through color palettes, labels, legends, etc.
Week 8: Strings and dates
- Work with strings and date/datetime objects
- Understand string basics, manipulate strings using
stringrfunctions, work with dates and times using thelubridatepackage
Week 9: Tidy data
- Understand tidy data structure and reshaping data
- Define tidy data and how to reshape untidy data into tidy form, reshape data from wide to long using
pivot_longer(), reshape data from long to wide usingpivot_wider(), handle missing values during reshaping
Week 10: Joining data
- Combine data from multiple datasets using joins
- Merge datasets using mutating joins, check quality of merge using filtering joins, append datasets by stacking rows
10 Course policies
10.1 Online collaboration/netiquette
You will communicate with instructors and peers virtually through a variety of tools such as GitHub, email, and Zoom web conferencing. The following guidelines will enable everyone in the course to participate and collaborate in a productive, safe environment.
- Be professional, courteous, and respectful as you would in a physical classroom.
- Online communication lacks the nonverbal cues that provide much of the meaning and nuances in face-to-face conversations. Choose your words carefully, phrase your sentences clearly, and stay on topic.
- It is expected that students may disagree with the research presented or the opinions of their fellow classmates. To disagree is fine but to disparage others’ views is unacceptable. All comments should be kept civil and thoughtful.
- It is imperative that we respect one another in this course, and all other spaces. One way to gain/show respect is to actively listen to one another. Please do not text, tweet, email, Facebook, LinkedIn, browse the internet, and such during class.
- In the unlikely event that Zoom is down, please be sure to check your email often for instructions on how we will complete that class session in an asynchronous manner.
Class Zoom guidelines
All synchronous class sessions will be held online, via Zoom. Below, we have outlined some general guidelines about Zoom learning. As we continue learning together, we can add to and change the below list. I’m open to your feedback and your experiences as we continue to learn how to learn via Zoom.
- Video: We will not require students to turn on their video during synchronous lectures. We encourage students to turn on their video only if they feel comfortable doing so – particularly during small group breakout rooms.
- Audio: We ask students to mute their microphones when they are not speaking. We encourage the use of earphones or headphones if you are in a space with background noise.
- Zoom outage: In the unlikely event that Zoom is down, the instructors will email the class with instruction for completing the class section in an asynchronous manner. Therefore, if Zoom is not functioning properly during the class period, be sure to check your email often.
- Internet connectivity: We understand that having access to a stable internet connection and/or electronic equipment is a privilege. With that in mind, we want to provide a space where everyone has the resources they need to do well in the class. If you have any issues with your internet connection and/or don’t have access to electronic equipment, please reach out to the instructors.
10.2 Academic accomodations
Center for Accessible Education
Students needing academic accommodations based on a disability should contact the Center for Accessible Education (CAE). When possible, students should contact the CAE within the first two weeks of the term as reasonable notice is needed to coordinate accommodations. For more information visit https://www.cae.ucla.edu/.
Located in A255 Murphy Hall: (310) 825-1501, TDD (310) 206-6083; http://www.cae.ucla.edu/
- Due to COVID-19, the CAE office is closed for in-person meetings
- CAE counselor, resources, and services are still available via email / virtual appointment
- Stay up-to-date with CAE newsletters & announcements at https://www.cae.ucla.edu/announcements-events/student
10.3 Academic integrity
UCLA policy
- UCLA is a community of scholars. In this community, all members including faculty, staff and students alike are responsible for maintaining standards of academic honesty. As a student and member of the University community, you are here to get an education and are, therefore, expected to demonstrate integrity in your academic endeavors. You are evaluated on your own merits. Cheating, plagiarism, collaborative work, multiple submissions without the permission of the professor, or other kinds of academic dishonesty are considered unacceptable behavior and will result in formal disciplinary proceedings.
This class
- Given that 90% of course grade is based on problem sets, the primary academic honesty concern that could come up in this class is copying problem set solutions from somebody else and passing this in as your own work.
11 Campus resources
11.1 Counseling and Psychological Services (CAPS)
As a student you may experience a range of issues that can cause barriers to learning, such as strained relationships, increased anxiety, alcohol/drug problems, depression, difficulty concentrating and/or lack of motivation. These mental health concerns or stressful events may lead to diminished academic performance or reduce a student’s ability to participate in daily activities. UC offers services to assist you with addressing these and other concerns you may be experiencing. If you or someone you know are suffering from any of the aforementioned conditions, consider utilizing the confidential mental health services available on campus.
Students in distress may speak directly with a counselor 24/7 at (310) 825-0768, or may call 911; located in Wooden Center West; https://www.caps.ucla.edu
- CAPS is open and has transitioned to Telehealth services ONLY
- Open Mon – Thurs: 8am-6pm and Fri: 8am-5pm
- As always, 24/7 crisis support is always available by phone at (310) 825-0768
11.2 Discrimination
UCLA is committed to maintaining a campus community that provides the stronget possible support for the intellectual and personal growth of all its members- students, faculty, and staff. Acts intended to create a hostile climate are unacceptable.
- To file an online incident report, visit: https://equity.ucla.edu/report-an-incident/
11.3 LGBTQ resource center
The LGBTQ resource center provides a range of education and advocacy services supporting intersectional identity development. It fosters unity; wellness; and an open, safe, inclusive environment for lesbian, gay, bisexual, intersex, transgender, queer, asexual, questioning, and same-gender-loving students, their families, and the entire campus community. Find it in the Student Activities Center, or via email lgbt@lgbt.ucla.edu.
- Visit their website for more information: https://www.lgbt.ucla.edu/ and virtual upcoming events
11.4 International students
The Dashew Center provides a range of programs to promote cross-cultural learning, language improvement, and cultural adjustment. Their programs include trips in the LA area, performances, and on-campus events and workshops.
- Due to COVID-19, the Dashew Center has transitioned its operations to a remote setting
- Visit their website for more information: https://www.internationalcenter.ucla.edu/
- For COVID updates, visit https://www.internationalcenter.ucla.edu/covid-19-updates
11.5 UCLA Undocumented Student Program
This program provides a safe space for undergraduate and graduate undocument students. USP supports the UndocuBruin community through personalized services and resources, programs, and workshops.
- Visit their website for more information: https://www.usp.ucla.edu/
- You can reach USP at usp@saonet.ucla.edu
11.6 Student legal services
UCLA Student Legal Services provides a range of legal support to all registered and enrolled UCLA students. Some of their services include:
- Landlord/Tenant Relations (Including challenges during COVID)
- Accident and Injury Problems
- Domestic Violence and Harassment
- Divorces and Other Family Law Matter
Due to COVID, Student legal Services is closed to walk-ins.
- All services are by appointment only
- For more information visit their website: http://www.studentlegal.ucla.edu/index.php
11.7 Students with Dependents
UCLA Students with Dependents provides support to UCLA studens who are parents, guardians, and caregivers. Some of their services include:
- Information, referrals, and support to navigate UCLA (childcare, family housing, financial aid)
- Access to information about resources within the larger community
- On-site application and verification for CalFresh (food stamps) & MediCal and assistance with Cal Works/GAIN
- A quiet study space
- Family friendly graduation celebration in June
For more information visit their website: https://www.swd.ucla.edu/
11.8 Campus maps
Lactation Rooms
Gender Inclusive restrooms
Campus accessibility
11.9 Title IX Resources
Title IX prohibits gender discrimination, including sexual harassment, domestic and dating violence, sexual assault, and stalking. If you have experienced sexual harassment or sexual violence, there are a variety of resources to assist you.
CONFIDENTIAL RESOURCES:You can receive confidential support and advocacy at the CARE Advocacy Office for Sexual and Gender-Based Violence, A233 Murphy Hall, CAREadvocate@careprogram.ucla.edu, (310) 206-2465. Counseling and Psychological Services (CAPS) also provides confidential counseling to all students and can be reached 24/7 at (310) 825-0768.
NON-CONFIDENTIAL RESOURCES: You can also report sexual violence or sexual harassment directly to the University’s Title IX Coordinator, 2255 Murphy Hall, titleix@conet.ucla.edu, (310) 206-3417. Reports to law enforcement can be made to UCPD at (310) 825-1491. These offices may be required to pursue an official investigation.
Faculty and TAs are required under the UC Policy on Sexual Violence and Sexual Harassment to inform the Title IX Coordinator should they become aware that you or any other student has experienced sexual violence or sexual harassment.